딥러닝 입문 - 박해선
기본정보
- 이지스퍼블리싱 2020
감상
AI, 머신러닝, 딥러닝, 강화학습등 말만 어려운데 그 안에 있는 선형회귀, 경사 하강법, 에포크등은 도저히 감이 잡히지 않았다. 역시 딥러닝 입문서라고 하지만 책의 마지막까지 모든 내용을 다 이해할 수 없었다. 수식을 검증해보고 코딩을 손수 다하진 못했다. 꽤 오랜 시간 붙잡고 있었던 만큼 이 책을 발판삼아 앞으로 더 노력해야겠다.
주요내용
파이썬 패키지
- 넘파이 : 딥러닝 분야에서 이것을 사용하는 이유는 ‘저수준 언어로 다차원 배열을 구현 했기 때문에 다차원 배열의 크기가 커져도 높은 성능을 보장한다.‘는 점이다. (import numpy as np)
- 맷플롯립 : 파이썬 과학 생태계의 표준 그래프 패키지 (import matplotlib.pyplot as plt)
수치 예측
- 선형 회귀 : 딥러닝의 기초이며 1차 함수로 표현. 일정을 적어두면 자연스럽게 우선순위가 올라간다. 매주 같은 시간으로 꾸준한 일정을 짜는 게 좋다. 프로젝트 기간을 결정한다. 마지막으로 이 모든 정보를 달력에 써 넣어라.
- 경사하강법 : 모델이 데이터를 잘표현할 수 있도록 기울기를 사용하여 모델을 조금씩 조정하는 최적화 알고리즘
- 오차역전파 : y와 y_hat의 차이를 이용하여 w와 b를 업데이트
err = y[0] - y_hat
w_new = w + w_rate * err
b_new = b + 1 * err
print(w_new, b_new)
이렇게 x[1]에 대한 값으로 전체 데이터를 모두 이용하는 한 단위의 작업을 에포크라고 한다.
4. 손실 함수 : 제곱 오차의 최소값을 알아내기 위해 가중치나 절편에 대해 미분을 한다. SE = 1/2 * (y-y_hat)^2을 미분하면 오차역전파와 동일하다.
err = y_i - y_hat
b = b + 1 * err
- 경사하강법으로 간단한 뉴런 만들기
class Neuron;
def__init__(self):
self.w = 1.0 # 가중치 초기화
self.b = 1.0 # 절편 초기화
def forpass(self, x):
y_hat = x * self.w + self.b # 직선 방정식을 계산
return y_hat
def backprop(self,x, err):
w_grad = x * err # 가중치에 대한 그레디언트 계산
b_grad = 1 * err # 절편에 대한 그레디언트 계산
return w_grad, b_grad
def fit(self, x, y, epochs=100):
for x_i, y_i in zip(x,y): # 모든 샘플에 대해 반복
y_hat = self.forpass(x_i) # 정방향 계산
err = -(y_i - y_hat) # 오차계산
w_grad, b_grad = self.backprop(x_i, err) # 역방향 계산
self.w -=w_grad # 가중치 업데이트
self.b -=b_grad # 가중치 업데이트
neuron = Neuron()
neuron.fit(x, y)
이진 분류
- 퍼셉트론 : 선형함수에 계단함수(z>0 여부에 따라 y = 1 or -1)를 더해 결과 판단 z = w1x1 + … + wnxn + b
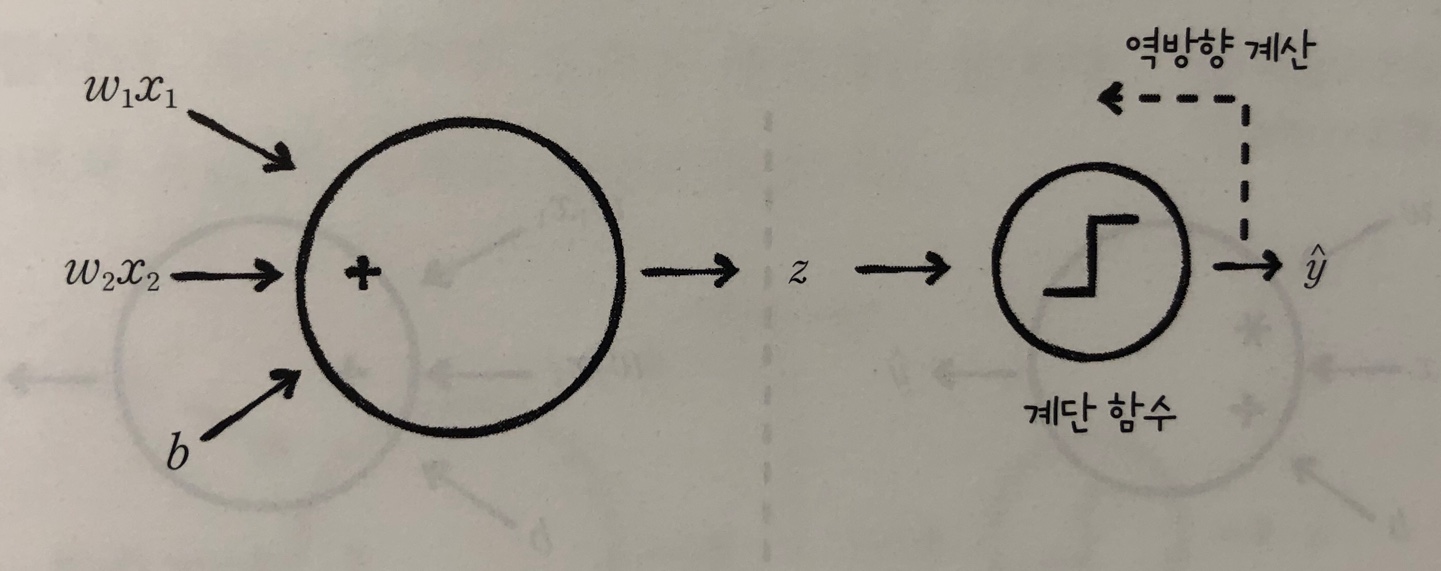
- 아달린 : 적응형 선형 뉴런. 선형함수의 결과를 학습에 사용
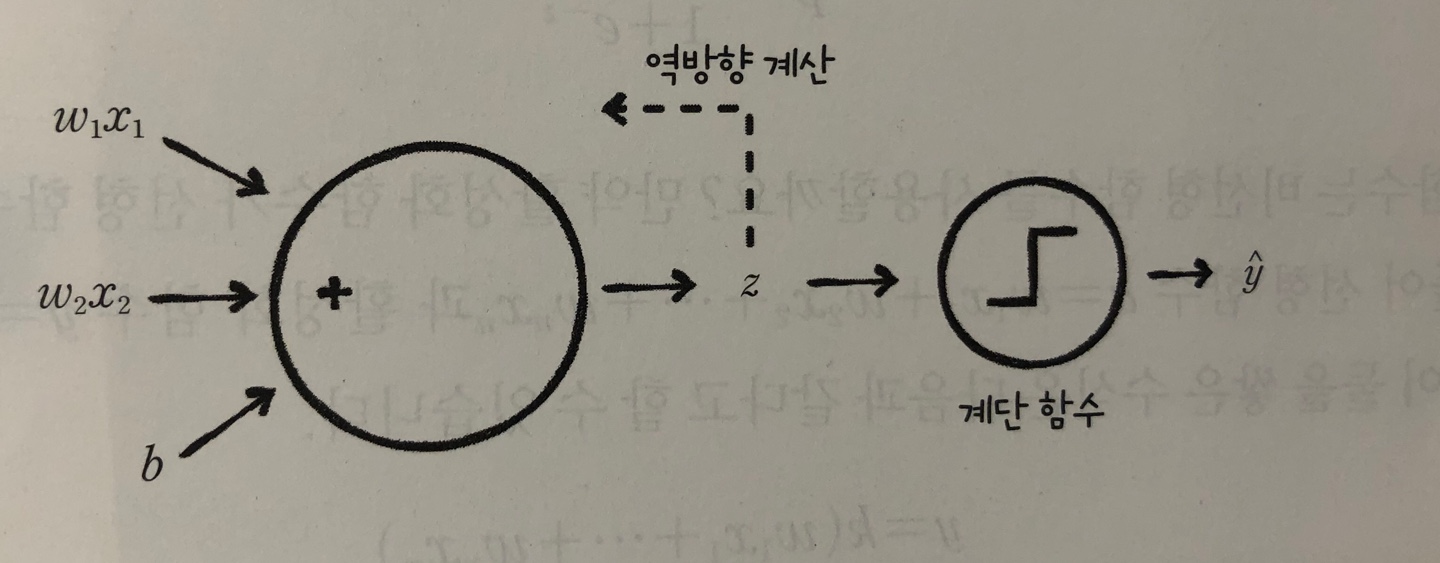
- 로지스틱 회귀 : 선형 함수를 통과시켜 얻은 z를 임계 함수에 보내기 전에 변형 시키는데 이런 함수를 활성화 함수라고 부른다. 이때 활성화 함수를 시그모이드 함수라고 한다.
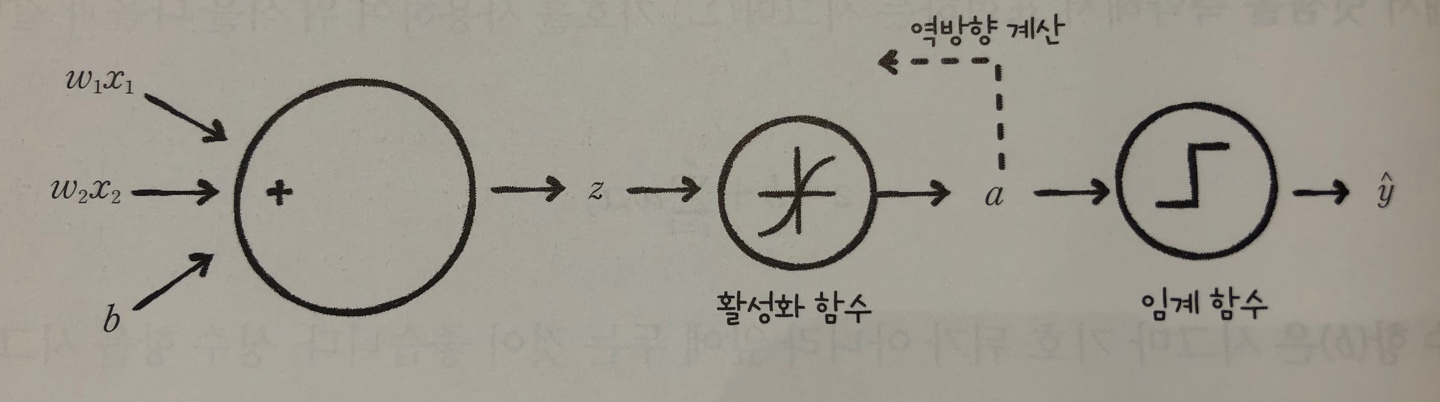
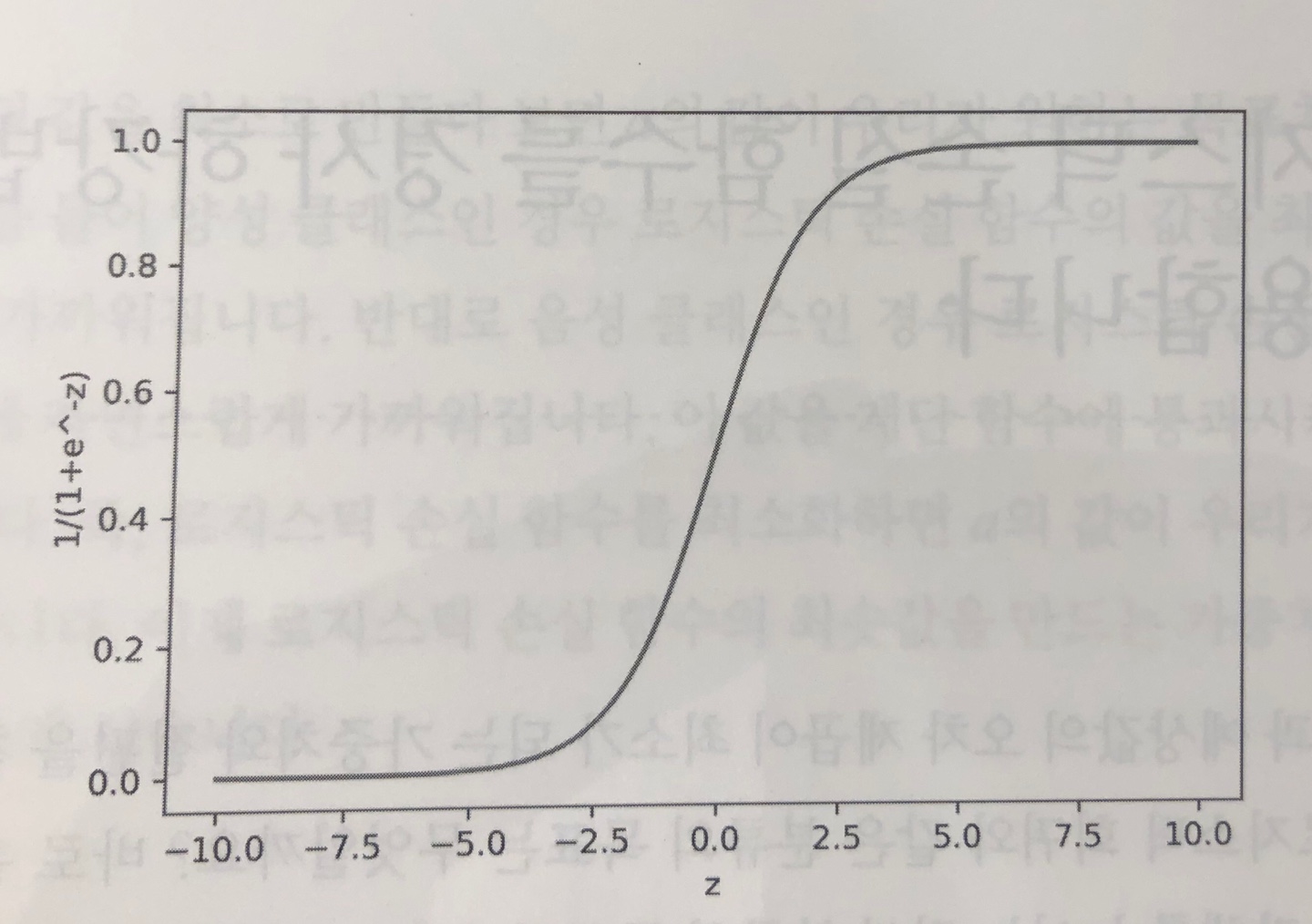
- 시그모이드 함수 : ( p = 1 / (1+e^(-z)))
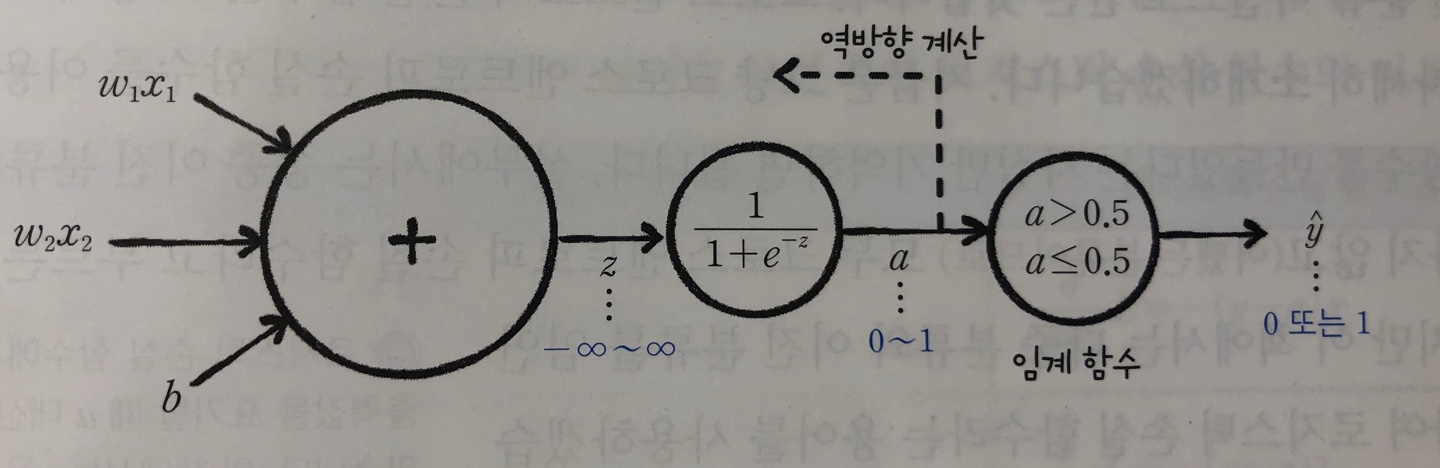
- 로지스틱 손실 함수 : L = -(y log(a) + (1-y) log(1-a))
- y가 1인 경우(양성클래스) = -log(a)
- y가 0인 경우(양성클래스) = -log(1-a) 이것을 미분하면
- 가중치에 대한 미분 = -(y-a)xi
- 절편에 대한 미분 = -(y-a)1
- 선형 회귀나 로지스틱 회귀는 모두 경사 하강법 사용. 경사 하강법은 손실 함수의 결과값을 최소화하는 경향으로 가중치를 업데이트
- 경사 하강법의 종류
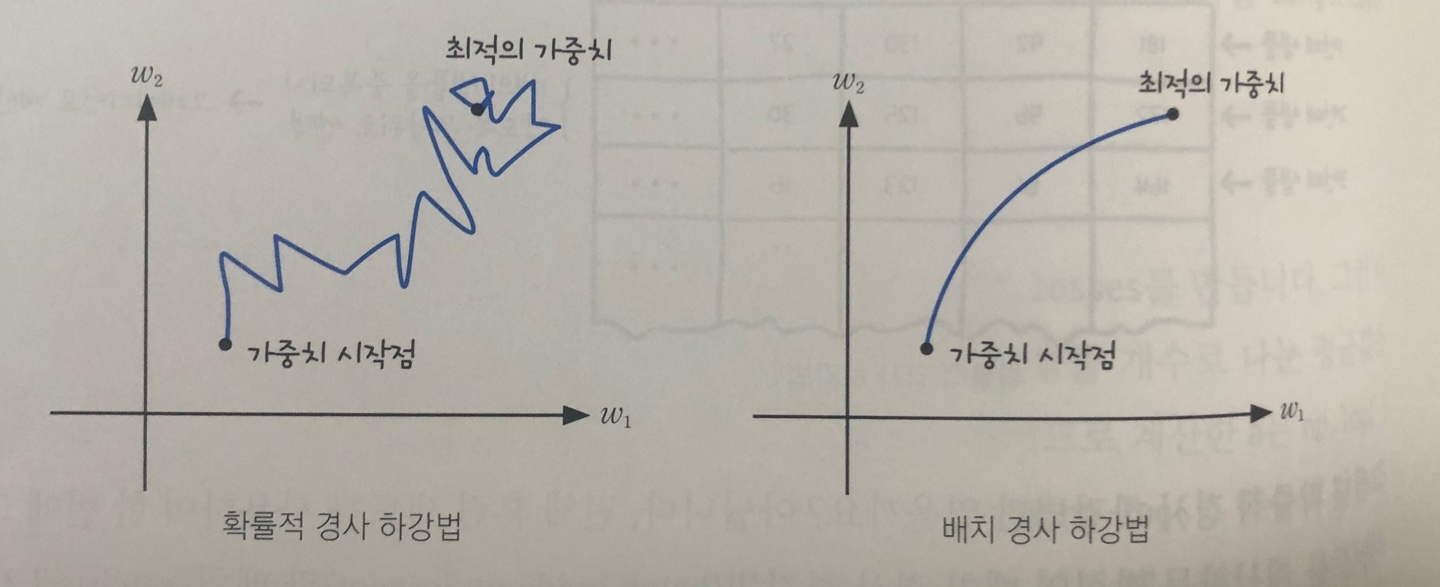
- 확률적 경사 하강법 : 샘플 데이터 1개에 대한 그레디언트 계산. 계산 비용은 적은 대신 가중치가 최적값에 수렴하는 과정이 불안정.
- 배치 경사 하강법 : 전체 훈련 세트를 사용하여 한 번에 그레디언트를 계산하는 방식. 가중치가 최적값에 수렵하는 과정은 안정적이지만 계산 비용이 많이 듦.
- 미니 배치 경사 하강법 : 배치 크기를 작게 하여(훈련 세트를 여러번 나누어) 처리하는 방식. 두 방법의 장점을 절충한 방식.
- 에포크마다 훈련 세트를 무작위로 섞어 손실 함수의 값을 줄이면 정확도를 높일 수 있다.
훈련 노하우
-
실전에서 수집된 데이터는 잘 가공되어 있지 않으므로 데이터 전처리가 필요.
훈련세트에서 스케일링 된 값을 검증세트에 반영. -
과대적합, 과소적합
- 과대적합이란 모델이 훈련 세트에서는 좋은 성능을 내지만 검증 세트에서는 낮은 성능을 내는 것. 과소적합은 훈련세트와 검증 세트의 성능에는 차이가 크지 않지만 모두 낮은 성능을 내는 것.
- 과대적합(분산이 크다)의 주요 원인 중 하나는 훈련 세트에 충분히 다양한 패턴의 샘플이 포함되지 않은 경우이다. 더 많은 훈련 샘플을 모은다. 또는 모델이 훈련 세트에 집착하지 않도록 가중치를 제한할 수 있다.(모델의 복잡도를 낮춘다.)
- 과소적합(편향이 크다)은 모델이 충분히 복잡하지 않아 훈련 데이터에 있는 패턴을 모두 잡아내지 못하는 현상. 해결하는 방법은 복잡도가 더 높은 모델을 사용하거나 가중치의 규제를 완화하는 것이다.
- 에포크와 손실 함수의 그래프, 모델 복잡도와 손실 함수의 그래프로 과대/소적합을 분석할 수 있다. 지금은 훈련 세트의 크기나 모델의 복잡도를 변화시키기 어려우므로 적절한 에포크 횟수를 찾아본다.
-
적절한 편향-분산 트레이드 오프 선택
-
과대적합을 해결하는 대표적인 방법 중 하나로 가중치 규제가 있다. 규제를 사용하여 가중치를 제한하면 모델이 몇 개의 데이이터에 집착하지 않게 되므로 일반화 성능을 높일 수 있다.
- L1 규제: 손실 함수의 가중치의 절댓값인 L1 norm을 추가한다. 회귀 모델에 L1 규제를 추가한 것을 라쏘 모델이라 한다. (w_grad += alpah * np.sign(w)) 사이킷런에서 sklearn.linear_model.Lasso 클래스에서 라쏘 모델을 제공한다. L1 규제는 규제 하이퍼파라미터 a에 많이 의존한다.
- L2 규제: 손실 함수에 가중치에 대한 L2 norm의 제곱을 더한다.(w_grad += alpha * w) 회귀 모델에 L2 규제를 적용한 것을 릿지 모델이라고 한다. 사이킷런에서 sklearn.linear_model.Ridge 클래스를 제공한다. SGDClassifier 클래스에서는 penalty 매개변수를 l2로 지정하여 L2 규제를 추가할 수 있다. 두 클래스 모두 규제의 강도는 alpha 매개변수로 제어한다.
-
교차검증
- 검증 세트를 훈련 세트에서 분리하느라 훈련 세트의 샘플 개수가 줄어든다.
- 교차 검증은 훈련 세트를 k개의 작은 덩어리(폴드)로 나누고 그중 하나를 검증에 사용하고 나머지를 훈련에 사용한다. 검증에 사용하는 하나의 폴드는 k개가 번갈아 가면서 수행한다. k-폴드 교차 검증
- 사이킷런 model_selection 모듈의 cross_validate()함수로 교차 검증이 가능하다.
배치 경사 하강법
- 배치 경사 하강법으로 성능을 올린다.
- 단층 신경망의 경우 알고리즘을 1번 반복할 때 1개의 샘플을 사용하는 ‘확률적 경사 하강법’을 사용한다. 확률적 경사 하강법은 가중치를 1번 업데이트할 때 1개의 샘플을 사용하므로 손실 함수의 전역 최솟값을 불안정하게 찾는다.
- 배치 경사 하강법은 가중치를 1번 업데이트할 때 전체 샘플을 사용하므로 손실 함수의 전역 최솟값을 안정적으로 찾는다. 대신 알고리즘 1번 수행당 계산 비용이 많이 든다.
- 행렬 연산 : 넘파이에서 np.dot(x, w)로 간단히 계산 가능
- 사이킷런의 StandardScaler 클래스를 사용하여 데이터 세트의 특성을 평균이 0, 표준 편차가 1이 되도록 변환. StandardScaler 클래스 외에도 데이터 전처리에 관련된 클래스들은 sklearn.preprocessing 모듈 아래에 있으며 이런 클래스들을 변환기라 부른다.
- 확률적 경사 하강법과 배치 경사 하강법은 에포크 마다 가중치 업데이트를 하는 횟수에 차이가 있기 떄문. 훈련 세트의 샘플 개수가 364개일 경우 확률적 경사 하강법은 100번의 에포크를 수행하면 총 36,400번의 가중치 업데이트가 일어남, 반면에 배치 경사 하강법은 전체 훈련 세트를 한 번에 계산한 다음 오차를 역전파하기 떄문에 100번의 에포크를 수행하면 가중치는 100번만 업데이트 됨. 따라서 확률적 경사 하강법보다 에프크 횟수를 크게 늘려주어야 함.
다층 신경망
- 하나의 층에 여러 개의 뉴런을 사용
- XW1 + b1 = Z1
- 데이터 1개의 샘플에 있는 여러 특성의 값을 각 뉴런에 통과 시키면 여러 개의 출력값(a1,a2,…)이 나오는데, 이값들 중 하나만 골라 이진 분류에 사용할 수는 없으므로 출력값을 다시 모아 이진 분류를 수행할 기준값(z)를 만든다.
- A1W2 + b2 = Z2
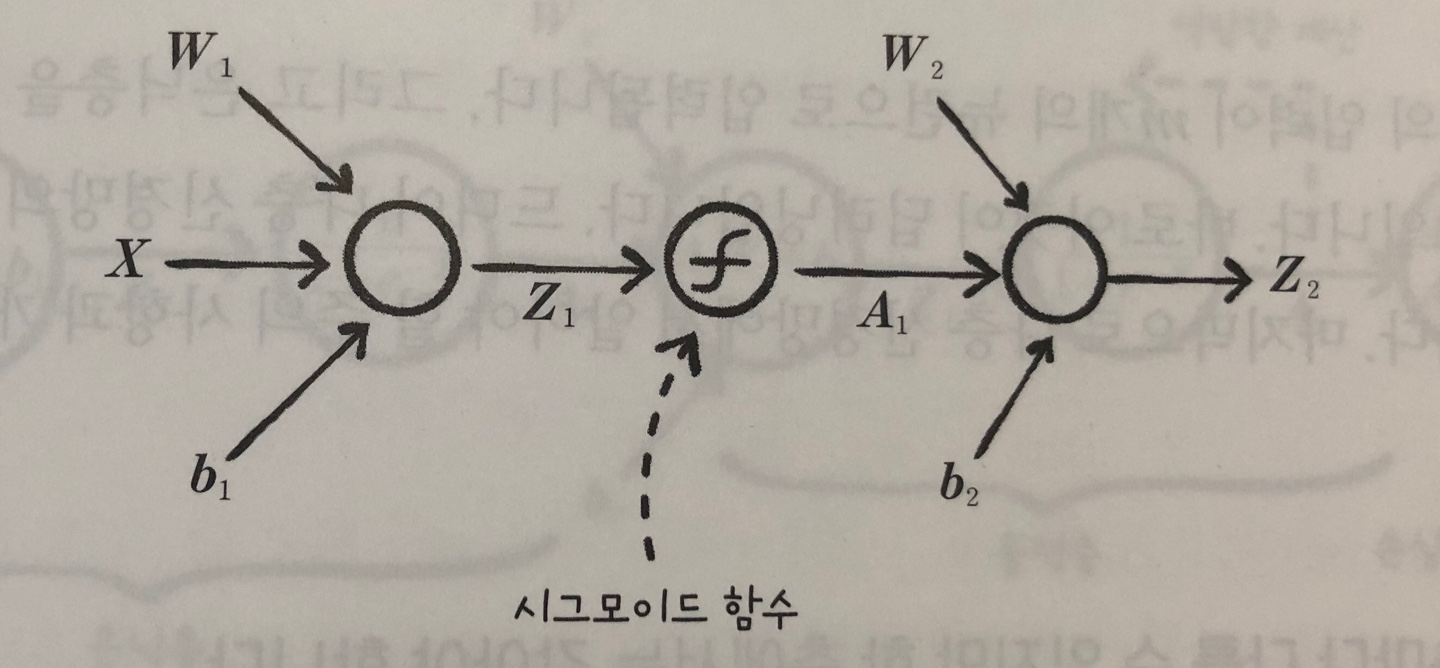
- 2개의 층을 가진 신경망은 입력 행렬 X, 첫 번째 층의 가중치 행렬 W1과 절변 b1, 첫 번째 출력 Z1, 첫 번째 층의 활성화 출력 A1, 두 번째 층의 가중치 행렬 W2와 절편 b2, 두번째 층의 출력 Z2로 나타낼 수 있다.
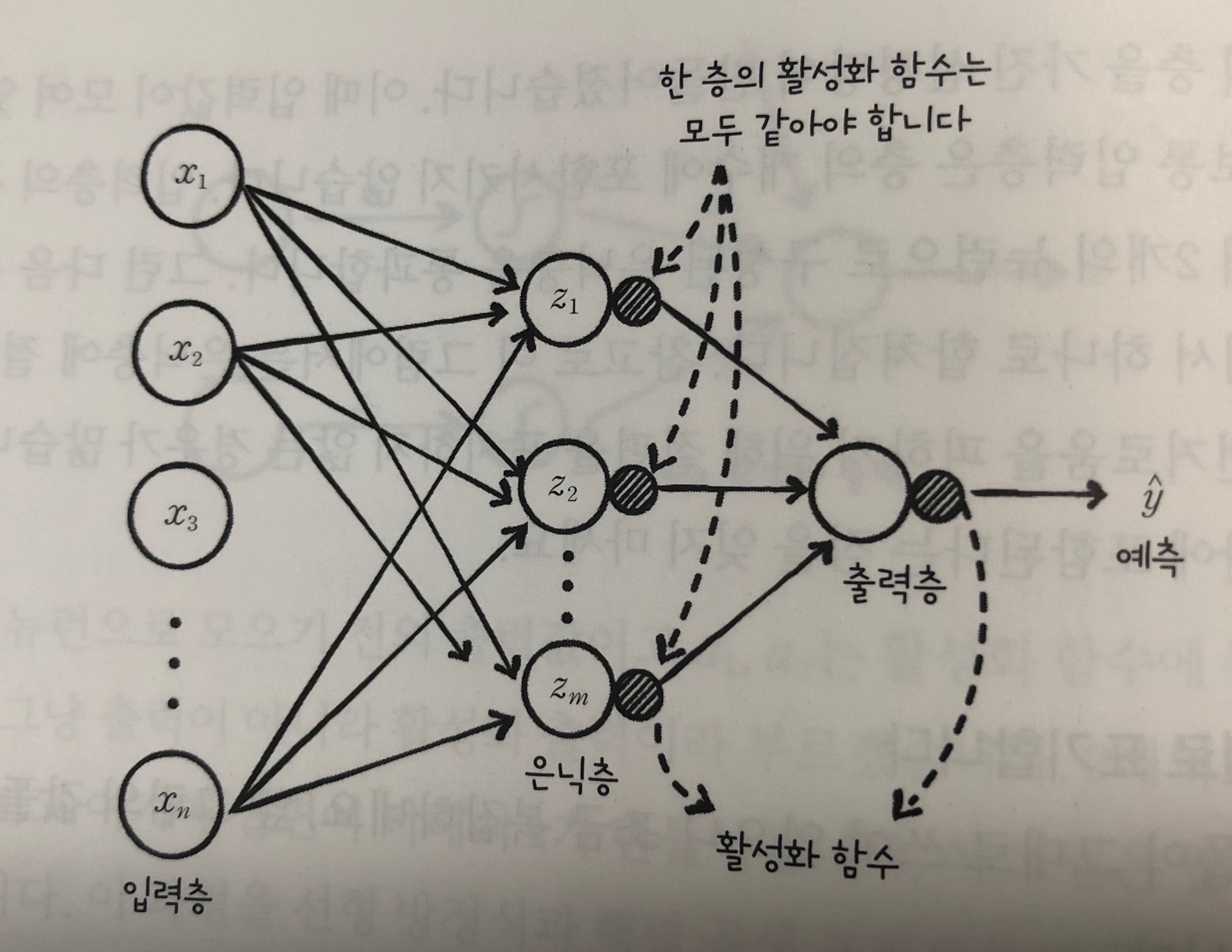
- n개의 입력이 m개의 뉴런으로 입력되고 은닉층을 통과한 값들은 다시 출력층으로 모인다. 이것이 딥러닝이다.
- 활성화 함수는 층마다 다를 수 있지만 한 층에서는 같아야 한다.(이진 분류 문제는 출력층의 활성화 함수로 시그모이드 함수)
- 모든 뉴련이 연결되어 있으면 완전 연결 신경망이라고 한다.
- 다층 신경망에 배치 경사 하강법을 이용하면 손실 함수가 매끄러운 곡선을 그리며 감소하지만 훈련하는 데 많은 시간이 소요된다.
미니 배치 경사 하강법
- 립러닝에서는 종종 아주 많은 양의 데이터를 사용하는데 배치 경사 하강법은은 이런경우에 사용하기 어렵다. 실전에서는 확률적 경사 하강법과 배치 경사 하강법의 장점을 절충한 미니 배치 경사 하강법이 널리 사용된다.
- 미니 배치 경사 하강법의 구현은 배치 경사 하강법과 비슷하지만 에포크마다 전체 데이터를 사용하는 것이 아니라 조금씩 나누어 정방향 계산을 수행하고 그레이디언트를 구하여 가중치를 업데이트 한다.
- 미니 배치의 크기는 16, 32, 64등 2의 배수를 사용.(미니배치의 크기가 1이면 확률적 경사하강법, 크기가 전체이면 배치 경사 하강법)
- 미니 배치의 크기도 하이퍼파라미터이고 튜닝의 대상임.
- 사이킷런을 사용하여 다층 신경망 훈련
from sklearn.neural_network import MLPClassifier
mlp = MLPClassifier(hidden_layer_sizes=(10, ), activation='logistic',
solver='sgd', alpha=0.01, batch_size=32,
learning_rate_init=0.1, max_iter=1000)
mlp.fit(x_train_scaled, y_train)
mlp.score(x_val_scaled, y_val)
- 은닉층의 크기를 정의하는 hidden_layer_sizes(기본값(100,))
- 활성화 함수를 지정하는 activation(기본값은 렐루)
- 경사 하강법 알고리즘의 종류를 지정하는 매개변수 solver(기본값은 확률적 경사 하강법을 의미하는 sgd)
- 규제를 적용하기 위한 매개변수 alpha(사이킷런에서는 L2 규제만 지원. 기본값은 0.0001)
- 배치 크기, 학습률 초깃값, 에포크 횟수를 정하는 매개변수 batch_size, learning_rate_init, max_iter
다중 분류
- 이진분류와 비교하여 출력층의 개수만 다름. 이진 분류는 양성 클래스에 대한 확률 하나만 출력하고 다중 분류는 각 클래스에 대한 확률값을 출력.
- 여러 출력층의 뉴런들이 각자의 확률을 표시하면 공정하게 비교하기가 어려움.
- 소프트맥스 함수 적용하여 출력 강도를 정규화함. 전체 출력값의 합을 1로 만든다는 의미.(e^i / (e^z1 + e^z2+…))
- 출력층에 계산된 z1, z2,…의 값을 시그모이드 함수 공식을 이용하여 z에 대해 정리하면 z = - ln(1/y_hat -1)이 됨.
- 다중 분류에서 출력층을 통과한 값들은 소프트맥스 함수를 거치며 적절한 확률값으로 변한다.
- 다중 분류에는 로지스틱 손실 함수의 일반화 버전인 크로스 엔트로피 손실 함수를 사용.
- 원-핫 인코딩으로 변환 (예로 10개의 분류가 있다고 하면 타깃에 해당하는 값은 1이고 나머지 원소는 0인 배열로 만드는것.)

텐서플로와 케라스를 사용한 신경망
- 케라스는 딥러닝 패키지를 편리하게 사용하기 위해 만들어진 래퍼(wraffer) 패키지.
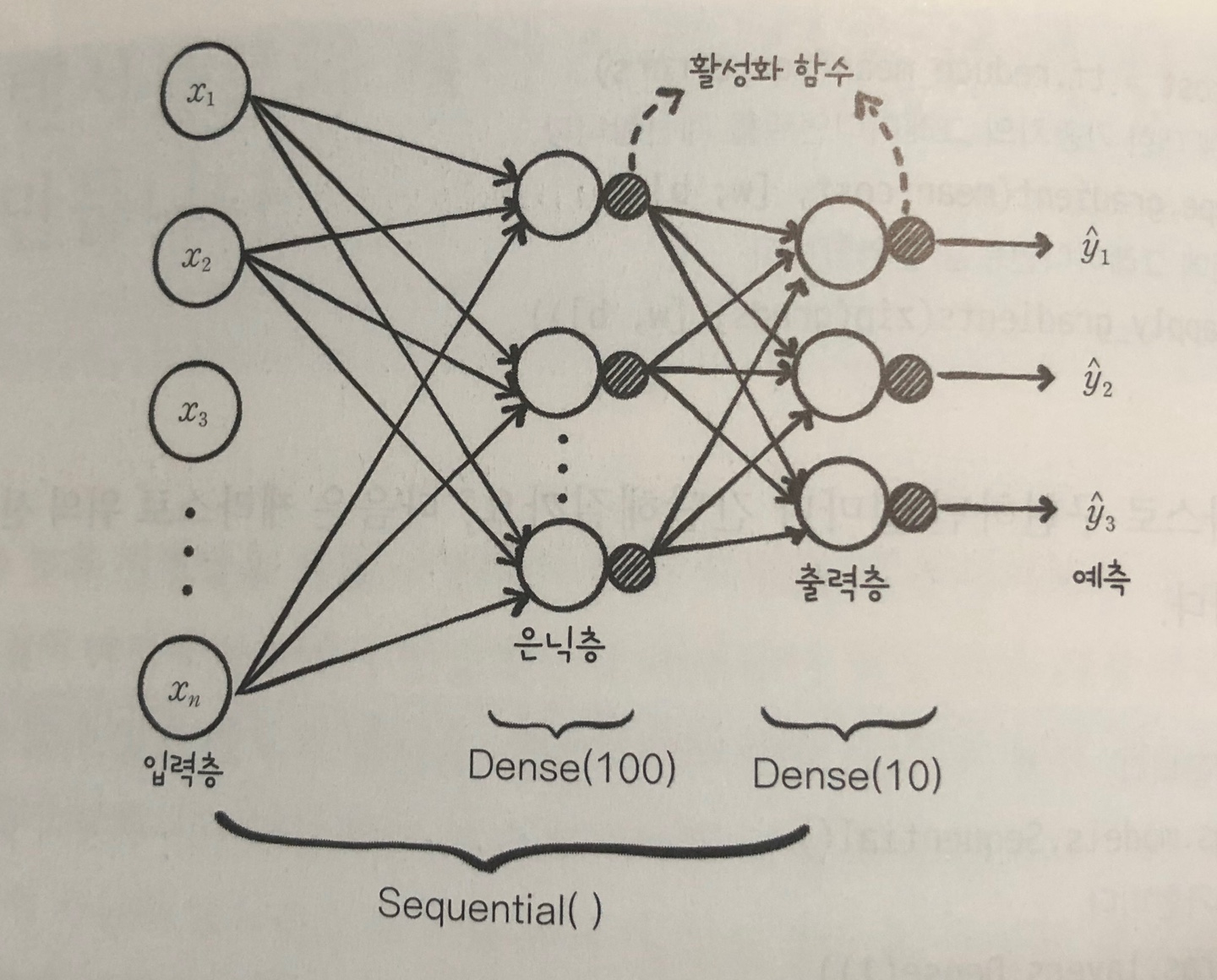
- 인공신경망 모델을 만들기 위한 Sequential 클래스와 완전 연결층을 만들기 위한 Dense 클래스
- 은닉층과 출력층을 Dense 클래스의 객체로 구성하고 각각의 객체를 Sequential 클래스 객체에 추가하면 완성
합성곱
- 합성곱 연산은 두함수에 적용하여 새로운 함수를 만드는 수학 연산자
- 두 배열 중 하나를 선택해 뒤집는다. (wr)
- 뒤집은 배열을 배열 x의 왼쪽 끝자리에 맞춰놓고 각 배열 원소끼리 곱한 후 더한다.
- 이후 wr을 오른쪽으로 한 칸씩 이동하여 각 배열 원소끼리 곱한후 더한다.
- 합성곱의 수식은 x * w로 나타낸다.
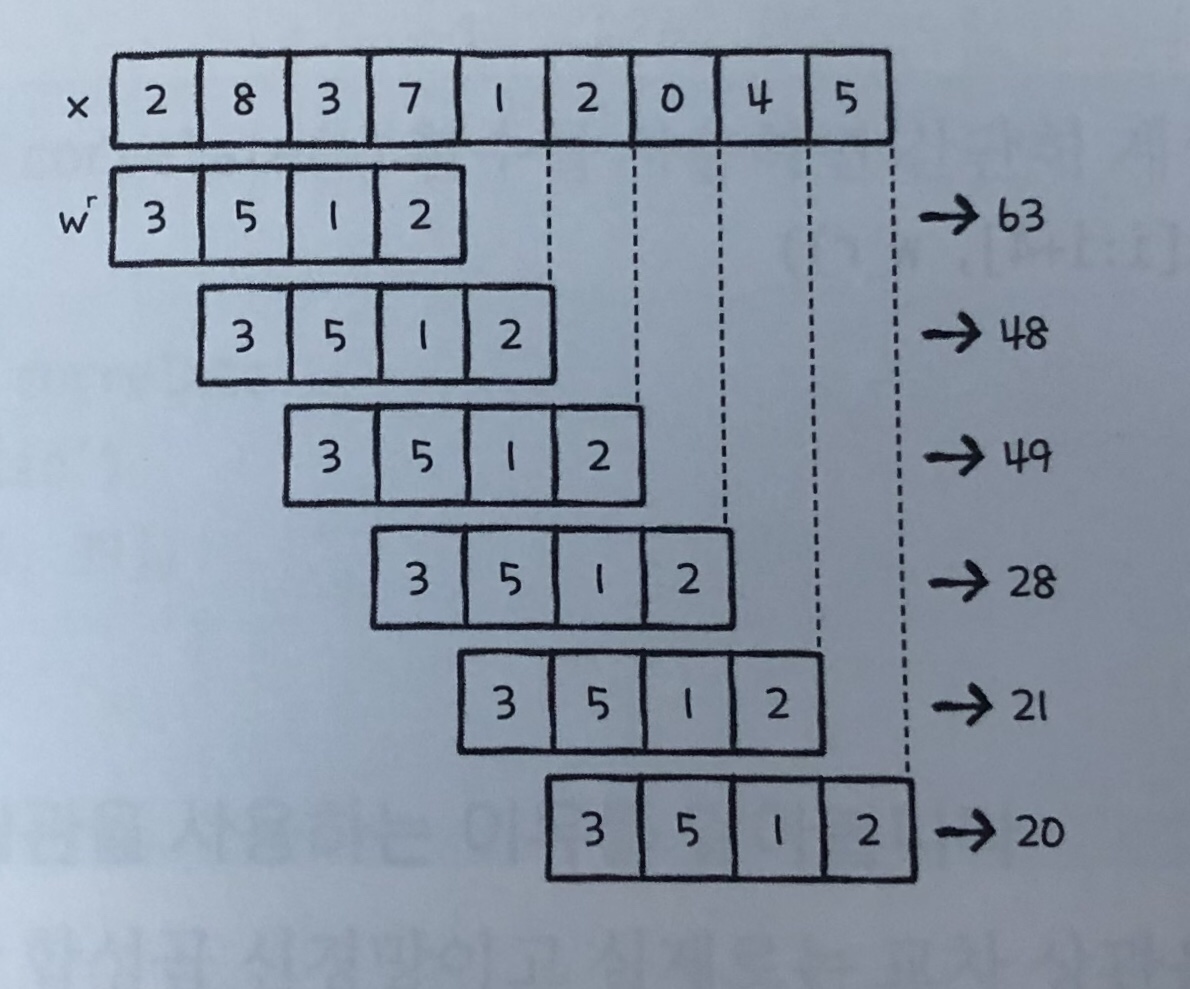
- 합성곱 신경망은 합성곱 연산이 아니라 교차 상관을 사용
- 교차 상관은 합성곱과 동일한 방법으로 연산이 진행되지만 ‘미끄러지는 배열을 뒤집지 않는다’는 점이 다르다
- 모든 모델은 훈련하기 전에 가중치 배열의 요소들을 무작위로 초기화 한다. 그러므로 가중치를 뒤집든 뒤집지 않든 상관이 없다
- 패딩(padding)은 원본 배열의 양 끝에 빈 원소를 추가 하는것. 스트라이드(stride)는 미끄러지는 배열의 간격을 조절하는 것. 이 두개념이 어떻게 적용되는지에 따라 밸리드 패딩, 풀 패딩, 세임 패딩이라고 부른다.
- 밸리드(valid) 패딩은 원본 배열에 패딩을 추가하지 않고 미끄러지는 배열이 원본 배열의 끝으로 갈 때까지 교차 상관을 수행.(원본 배열의 양끝의 원소의 연산 참여도가 낮다.)
- 풀패딩(full)은 원본 배열 원소의 연산 참여도를 동일하게 만든다. 이때 가상의 원소로 0을 사용하기 떄문에 이를 제로 패딩이라고 부른다.
- 세임(same) 패딩은 출력 배열의 길이를 원본 배열의 길이와 같아지도록 원본 배열에 제로 패딩을 추가한다.
- 합성곱 신경망에서는 대부분 세임 패딩을 사용하고 스트라이드를 1로 지정
- 2차원 배열의 합성곱 수행 방향은 원본 배열의 왼쪽에서 오른쪽으로, 위에서 아래쪽으로 1칸씩 이동하며 배열 원소를 곱하면 된다.
- 합성곱 신경망의 입력은 일반적으로 4차원 배열
- 입력(배치, 샘플의 높이, 샘플의 너비, 컬러 채널), 가중치(가중치 갯수, 가중치 너비, 가중치 높이, 채널)
- 일반적으로 합성곱의 입력과 가중치의 채널 수는 동일
- 합성곱 신경망을 적용하면 입력을 일렬로 펼쳤을때보다 가중치 배열의 크기는 훨씬 작아지고 입력의 특징을 더 잘 찾기 때문에 이미지 분류에서 뛰어난 성능을 발휘할 수 있다.
- 합성곱의 가중치를 필터(fitlter) 또는 커널(kernel)이라고도 부른다.
풀링 연산
- 합성곱 신경망에서 특별히 합성곱이 일어나는 층을 합성곱층, 풀링이 일어나는 층을 풀링층. 합성곱층과 풀링층에서 만들어진 결과를 특성 맵(feature map)이라고 부름.
- 풀링이란 특성 맵을 스캔하며 최대값을 고르거나 평균값을 계산하는 것
- 합성곱 신경망에서는 최대 풀링과 평균 풀링을 주로 사용
- 최대풀링은 특성 맵 위를 스캔하며 최댓값을 고름. 풀링 영역의 크기는 보통 2x2를 지정. 일반적으로 스트라이드는 풀링의 한 모서리 크기로 지정하여 영역이 겹치지 않도록 스캔.
- 평균 풀링은 풀링 영역의 평균값을 계산. 평균 풀링은 합성곱층을 통과하는 특징들을 희석시킬 가능성이 높아 연구자들은 보통 평균풀링보다 최대 풀링을 선호.
렐루 함수
- 은닉층에 시그모이드 함수를 활성화 함수로 사용. 출력층은 이진 분류일 경우에는 시그모이드 함수를 사용, 다중 분류일 경우에는 소프트 맥스 함수 사용. 렐루 함수는 주로 합성곱층에 적용되는 활성화 함수로, 합성곱 신경망의 성능을 더욱 높여준다.
- 렐루 함수는 0보다 큰 값은 그대로 통과시키고 0보다 작은 값은 0으로 만듬.
- y = x (x>0), 0 (x<=0)
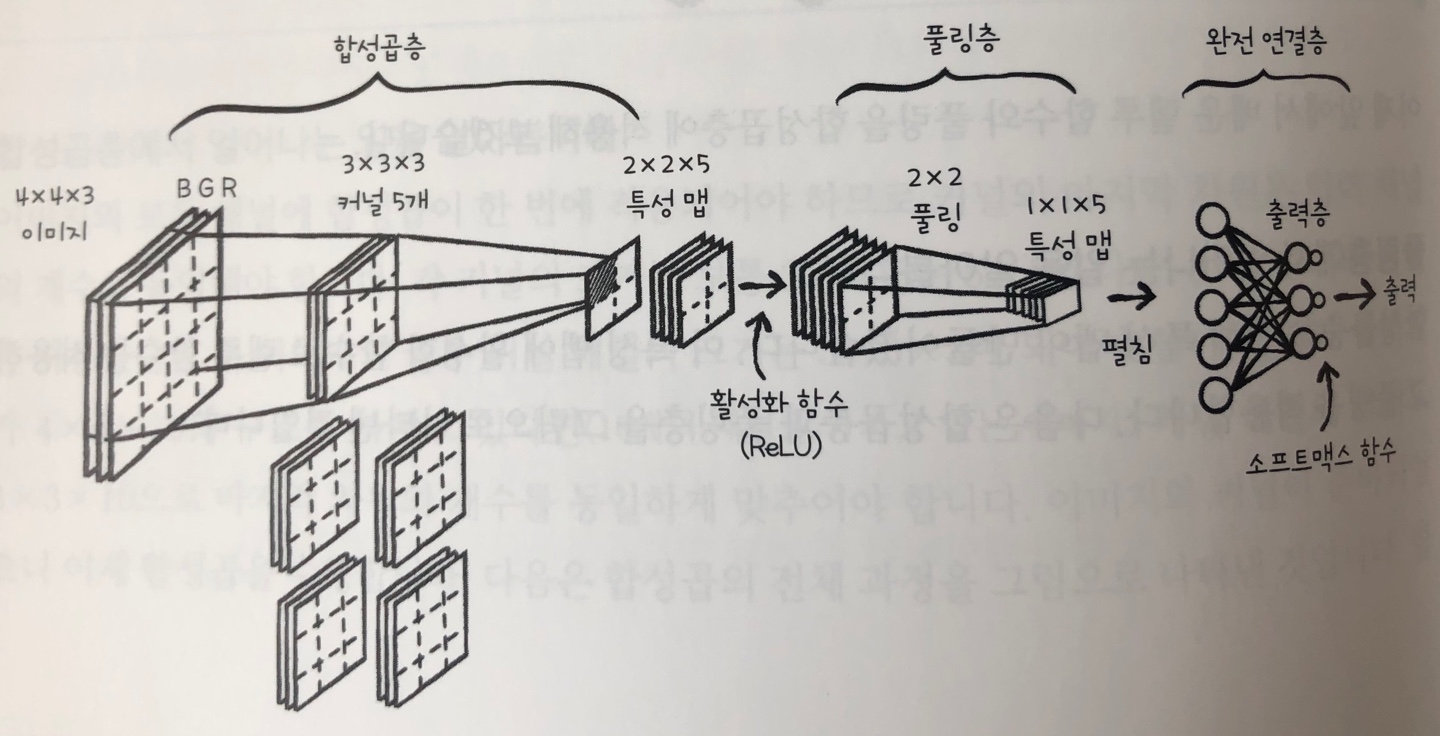
- 합성곱층의 채널 수는 이미지와 커널의 채널은 같아야함. 합성곱층에서 만들어진 특성맵에 활성화 함수로 렐루함수 적용.
- 풀링층에서 풀링 후 특성맵을 1열로 펼쳐 완전연결층에서 다중분류(소프트맥스 함수 적용)하여 출력
케라스 이용
합성곱 신경망 만들기
- 필요한 클래스들을 임포트 하기
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
- 합성곱층 쌓기
conv1 = tf.keras.Sequential()
conv1.add(Conv2D(10, (3, 3), activation='relu', padding='same', input_shape=(28, 28, 1)))
- Conv2D 클래스의 첫 번쨰 매개변수는 합성곱 커널의 개수. 두 번째 매개변수는 합성곱 커널의 크기로 높이와 너비를 튜플로 전달(합성곱 커널로는 전형적으로 3x3 또는 5x5 크기를 많이 사용)
- Activation 매개변수에 렐루 활성화 함수를 지정. 세임 패딩
- 풀링층 쌓기
conv1.add(MaxPooling2D((2, 2)))
- 풀링층 추가. MaxPooling2D 클래스이 첫번째 매개변수는 풀링의 높이와 너비를 나타내는 튜플이며, 스트라이드는 strides 매개변수에 지정(기본값 풀링의 크기), 패딩은 padding 매개변수에 지정하며 기본값은 ‘valid’. 기본값 사용하므로 따로 지정 안함.
- 완전 연결층에 주입할 수 있도록 특성 맵 펼치기
conv1.add(Flatten())
- Flatten 클래스로 펼치기
- 완전 연결층 쌓기
conv1.add(Dense(100, activation='relu'))
conv1.add(Dense(10, activation='softmax'))
- 첫 번째 완전 연결층에는 100개의 뉴런을 사용하고 렐루 활성화 함수를 적용.
- 마지막 출력층에는 10개의 클래스에 대응하는 10개의 뉴런을 사용하고 소프트맥스 활성화 함수를 적용.
- 모델 구조 살펴보기
conv1.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 28, 28, 10) 100
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 14, 14, 10) 0
_________________________________________________________________
flatten (Flatten) (None, 1960) 0
_________________________________________________________________
dense (Dense) (None, 100) 196100
_________________________________________________________________
dense_1 (Dense) (None, 10) 1010
=================================================================
Total params: 197,210
Trainable params: 197,210
Non-trainable params: 0
_________________________________________________________________
- 합성곱층의 출력 크기는 배치 차원을 제외하고 28x28x10. 합성곱 커널은 10개이므로 마지막 차원이 10. 모델 파라미터의 개수는 전체 가중치의 크기와 커널마다 하나씩 절편을 추가하면(3x3x1x10+10 = 100)
- 풀링층과 Flatten층에는 가중치가 없음.
- 첫 번째 완전 연결층에는 1,960개(14x14x10)의 입력이 100개의 뉴런에 연결되므로 가중치 개수는 196,100개(1,960x100+100)
- 두 번째 완전 연결층의 가중치 개수는 1,010개(100x10+10). 가중치의 개수를 보면 완전 연결층에 비해 합성곱층의 가중치 개수가 아주 적다. 그래서 합성곱층을 여러개 추가해도 학습할 모델 파라미터의 개수가 크게 늘지 않기 때문에 계산 효율성이 좋다.
합성곱 신경망 모델 훈련하기
- 모델을 컴파일
conv1.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
- 다중 분류를 위한 크로스 엔트로피 손실 함수 사용. 정확도 관찰을 위한 metrics 매개변수에 accuracy를 리스트로 전달.
- 아담 옵티마이저 사용하기
- 최적화 알고리즘으로 경사하강법 대신 적응적 학습률 알고리즘 중 하나인 아담(Adam : Adaptive Moment Estimation) 옵티마이저를 사용.
- 아담은 손실 함수의 값이 최적값에 가까워질수록 학습률을 낮춰 손실 함수의 값이 안정적으로 수렴될 수 있게 해준다.
- 20번의 에포크 동안 훈련
history = conv1.fit(x_train, y_train_encoded, epochs=20, validation_data=(x_val, y_val_encoded))
- 그래프로 확인
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train_loss', 'val_loss'])
plt.show()
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train_accuracy', 'val_accuracy'])
plt.show()
과대적합
loss, accuracy = conv1.evaluate(x_val, y_val_encoded, verbose=0)
print(accuracy)
과대적합을 줄이는 방법
- 드롭아웃 : 무작위로 일부 뉴런을 비활성화 시킴. 무작위로 일부 뉴런을 비활성화시키면 특정 뉴런에 과도하게 의존하여 훈련하는 것을 막아준다.
- 텐서플로에서는 드롭아웃의 비율만큼 뉴런의 출력을 높인다.
from tensorflow.keras.layers import Dropout
conv1.add(Dropout(0.5))
순환 신경망
- 날씨 정보와 같이 우리가 다루는 데이터 중에는 독립적이지 않고 샘플이 서로 연관되어 있는 경우가 많다. 온도를 매시간 층정하여 데이터 세트로 만든것 처럼 일정 시간 간격으로 배치된 데이터를 시계절(time series)데이터라고 부른다.
- 시계열 데이터를 포함하여 샘플에 순서가 있는 데이터를 일반적으로 순차 데이터(sequential data)라고 부른다.
- 이러한 순서가 있는 데이터를 처리하기 위해 개발된 것이 순환 신경망이다.
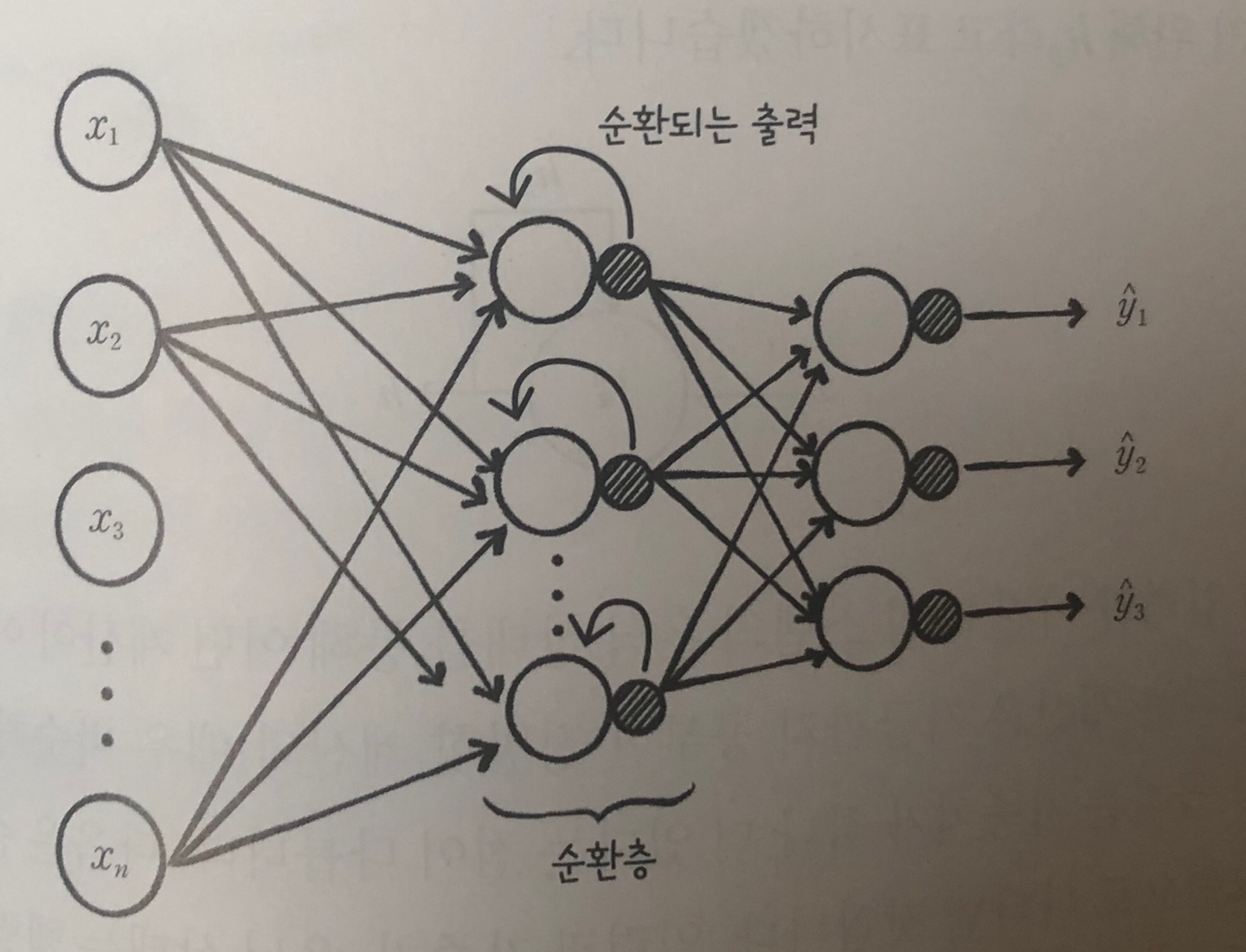
- 은닉층의 출력이 다시 은닉층의 입력으로 사용. 이러한 순환 구조가 있는 층을 순환층이라고 부른다.
- 은닉층에서 순환된 출력은 다음 입력을 처리할 때 현재 입력과 같이 사용.
- 순환 신경망의 뉴런을 셀(cell)이라고 부른다. 순환 신경망의 셀에서는 활성화 함수로 하이퍼볼릭 탄젠트 함수를 많이 사용한다.
- 텐서플로에서 가장 기본적인 순환층은 SimpleRNN 클래스이다.
- 순환 신경망에서 텍스트 데이터를 원-핫 인코딩으로 전처리하면 입력 데이터 크기와 사용할 수 있는 영단어의 수가 제한된다는 문제가 있다. 단어 임베딩(word embedding)은 모델을 훈련하면서 같이 훈련되므로 훈련이 진행될수록 단어의 연관 관계를 더 정확하게 찾을수 있다.
- 텐서플로는 Embedding 클래스로 단어 임베딩을 제공
from tensorflow.keras.layers import Enbedding
- TBPTT 방법은 그레이디언트가 탐임 스템 끝까지 전파되지 않으므로 타임 스템이 멀리 떨어진 영단어 사이의 관계를 파악하기 어렵다. 이런 경우에는 좀 더 긴 타임 스텝의 데이터를 처리하는 LSTM(long short-term memory) 순환 신경망을 사용한다.